



接口说明
流控信息
请求参数
| 字段名称 | 字段详情 |
|---|---|
JsonStrstring | 完整 JSON 字符串信息,具体内容参见下方详细信息。 示例值:{“conditions”:“xxxxx”,"rules":"xxxx"} |
BaseMeAgentIdinteger<int64> | 业务空间 Id 注意
该字段类型为 Long,在序列化/反序列化的过程中可能导致精度丢失,请注意数值不得大于 9007199254740991。 |
请求说明
请求参数 JSON 字符串信息
| 属性 | 值类型 | 是否必选 | 描述 |
|---|---|---|---|
| appKey | String | 是 | 业务方或者业务场景的标记。 |
| conditions | List | 是 | 所有条件的详细配置信息,具体内容参见下方的条件的详细配置信息字段 ConditionBasicInfo 描述。 |
| rules | List | 是 | 规则的配置信息,具体内容参见下方的规则的配置信息字段 RuleInfo 描述。 |
一、条件的详细配置信息字段 ConditionBasicInfo 说明
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| cid | String | 是 | "1" | 条件的 ID,必须数字字符(建议从 1 开始以正整数向上累加),此数字在规则上传后会被修改为系统自生成 Id。 |
| check_range | CheckRange | 是 | 具体内容参见下方的条件检查范围 CheckRange 描述 | 条件的检查范围。 |
| operators | List | 是 | 具体内容参见下方的条件所包含算子 OperatorBasicInfo 描述 | 条件包含的算子。 |
| lambda | String | 是 | 一个算子:"1",多个算子:1&&2&&3 | 条件中算子的逻辑关系,由算子 ID(oid)与逻辑运算符(与、或、非)组成的表达式,示例值中的 1、2、3 均代表算子 ID(oid),oid 在条件所包含算子 OperatorBasicInfo 描述中有详细说明。 |
条件检查范围 CheckRange 描述:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| role | String | 否 | 客服 | 适用角色,条件的作用角色范围,可取值:“客服”;“客户”。不传表示所有角色。 |
| anchor | Anchor | 否 | 具体内容参见下方的前置条件 Anchor 描述 | 前置条件详细信息。 |
| range | String | 否 | {"from":1,"to":3} | 检测范围,具体使用说明请查看本文档特殊说明中的检测范围 range 使用说明。 |
前置条件 Anchor 描述:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| cid | String | 是 | "3" | 前置条件的条件 id(cid),用于确定 anchor 的条件。 |
| location | String | 是 | AROUND | 用来指定前置条件命中时,当前条件检测前置条件命中句子的之前 XX 句、之后 XX 句、前后部分句子、当前句,取值:BEFORE(前置条件命中句子之前)、AROUND(前置条件命中位置前后)、AFTER(前置条件命中句子之后)、CURRENT(前置条件命中的当前句)。通过该字段限定一个范围,然后配合上面的 range 中的 from、to 来指定具体的句子。 |
| hit_time | Integer | 是 | 3 | 前置条件的命中次数,有以下三种情况:1、正整数 1~N 代表前置条件第一(N)次命中;2、0 代表前置条件每次命中;3、-1 代表前置条件任意一次命中。 |
条件所包含算子 OperatorBasicInfo 描述:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| oid | String | 是 | "1" | 算子的 ID,必须数字字符(建议从 1 开始以正整数向上累加),此数字在规则上传后会被修改为系统自生成 ID。 |
| name | String | 是 | 我是算子名称 | 算子名称、描述。 |
| type | String | 是 | INCLUDE_KEYWORDS | 算子类型,具体内容参见下方的算子类型以及算子具体内容 Param 描述。 |
| param | Param | 是 | 具体内容参见下方的算子类型以及算子具体内容 Param 描述 | 算子表达式具体内容。 |
算子类型以及算子具体内容 Param 描述:
param 中的属性较多,有一些是公用属性,有一些是特定算子类型专用的,所以我们按照算子类型维度,来逐一说明每个算子类型都可以使用哪些属性,并且提供配置示例供您参考,以下标题为算子名称(name)、算子类型(type),内容为该算子可用参数列表,以及使用示例:
1、关键词检查:
包含任意一个关键字(HIT_ANY_KEYWORDS)、包含全部关键字/包含任意 N 个关键字/全部不包含(INCLUDE_KEYWORDS)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| keywords | List | 是 | ["你好","您好","上午好"] | 关键词列表 |
| contextChatMatch | Boolean | 否 | false | 是否多句分析,用来指定分析方式,可选值:true(多句分析);false(单句分析),默认 false。详见下方的分析方式详细说明 |
| keywordMatchSize | Integer | 否 | 3 | 匹配关键字的数量,不同的检测类型与该参数取值的关系:包含任意一个关键字(取值为 1)、包含全部关键字(取值为-1)、包含任意 N 个关键字(取值为大于等于 1 并且小于等于关键字的个数正整数)、全部不包含(取值为 0)。默认值根据关键字检测类型(type 值)的不同而不同:HIT_ANY_KEYWORDS(1)、INCLUDE_KEYWORDS(-1) |
| in_sentence | Boolean | 否 | true | 匹配时是否限制在单句话中(单句话是指中间没有逗号、句号等,以逗号、句号等标号分开的算不同句子);可取值:true(限定在一个句子中);false(不限定);默认 false。若 contextChatMatch 为 true,则该参数无效,因为分析方式为多句分析时,与单句话生效是冲突的。 |
| keywordExtension | Integer | 否 | 0 | 是否开启同义词扩展,可取值:1(开启);0(关闭);默认:0。 |
分析方式详细说明
- 单句分析、多句分析针对的是当前条件所限定的句子。
- 限定句子:通过当前条件的适用角色、前置条件及检测范围所限定的 1 个或多个句子。
- 单句分析:对限定句子逐句进行分析,例如检测包含全部关键词,只有限定句子中的某一句包含了全部的关键词,才算命中。
- 多句分析:将限定句子合并为一个段落进行一次分析,例如检测包含全部关键词,只要合并后的段落中包含全部的关键词就算命中。
请求示例: ①单句分析、包含任意一个关键字
{
"keywords":[
"您好",
"你好",
"上午好"
],
"contextChatMatch":false,
}

②多句分析、包含全部关键字
{
"keywordMatchSize":-1,
"keywords":[
"您好",
"你好",
"上午好"
],
"contextChatMatch":true
}

③单句分析、包含任意 2 个关键字、单句话内生效、开启同义词扩展
{
"keywordMatchSize":2,
"keywordExtension":1,
"keywords":[
"您好",
"你好",
"上午好"
],
"in_sentence":true,
"contextChatMatch":false
}

④单句分析、全部不包含
{
"keywordMatchSize":0,
"keywords":[
"您好",
"你好",
"上午好"
],
"contextChatMatch":false
}

2、正则表达式检查(REGULAR_EXPRESSION)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| regex | String | 是 | 请看下方代码示例 | 命中的正则表达式。 |
| notRegex | String | 否 | 请看下方代码示例 | 排除的正则表达式。 |
| in_sentence | Boolean | 否 | true | 默认为 false,匹配时是否限制在单句话中(单句话是指中间没有逗号、句号等,以逗号、句号等标号分开的算不同句子);true:限定在一个句子中,false:不限定,默认:false。 |
{
"regex":"请问.*(车牌号|发动机号|驾驶证号码)",
"notRegex":"发一下|告诉我",
"in_sentence":true
}

3、文本相似度检查(SIMILAR_MATCH)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| similarlySentences | List | 是 | 请看下方代码示例 | 示例语句,最多可输入 200 句,每个示例语句最大长度为 50 字符。 |
| score | Integer | 否 | 80 | 相似度分值,默认为 80。 |
{
"score":80,
"similarlySentences":[
"我想投诉你们部门",
"我要投诉你们",
"我要举报你们部门",
"我要打 12315 举报你们",
"我要到工商管理部门投诉你们"
]
}

4、上下文重复(ADVANCED_REPEAT_DETECT)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| from | Integer | 否 | 3 | 表示重复的两句话间隔在几句以内时才算违规,默认:2,即从当前局往前数 2 句(包含)之内重复算违规。 |
| hit_time | Integer | 否 | 2 | 表示第几次重复出现时才算违规,默认:1。 |
| threshold | Integer | 否 | 5 | 最小字数,小于此值的句子不检查,默认:4。 |
| excludes | List | 否 | ["好的我知道了","好的我知道了"] | 表示例外句子,即例外句子重复出现时不算违规,默认:空。 |
{
"from":3,
"hit_time":2,
"threshold":5,
"excludes":[
"好的好的我知道了",
"好的我知道了"
]
}

5、通话静音检查(INTERVAL_GREATER)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| interval | Integer | 是 | 5000 | 静音时长(毫秒)。 |
| different_role | Boolean | 否 | false | 是否区分角色,true:区分角色,false:不区分角色;为 true 则目标句子如果与本句是同一个角色说的话就不参与计算。 |
| target | Integer | 否 | 1 | 目标句子是当前句子的前多少句,为 0 时间隔等于本句的结束时间-本句的开始时间。 |
| from_end | Boolean | 否 | false | 指定时间间隔的计算方式是否用本句的结束时间减目标句子的结束时间。 |
{
"interval":5000,
"different_role":false,
"target":1,
"from_end":false
}

6、语速检查(SPEECH_SPEED_CHECK)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| velocityInMint | Integer | 是 | 370 | 每分钟的语速值(字数),用以判断本句的语速是否超过指定值。 |
| minWordSize | Integer | 否 | 4 | 表示当一句话少于多少字时不检测。 |
| average | Boolean | 否 | false | true:检测整个对话的平均语速;false:检测单句话的语速。 |
{
"velocityInMint":370,
"average":false,
"minWordSize":4
}

7、抢话检查(GRAB_WORDS)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| interval | Integer | 是 | 5000 | 交叉时间,也就是抢话中客户说话的结束时间减去客服说话的开始时间(毫秒)。 |
| threshold | Integer | 否 | 4 | 表示当抢话句子的字数大于多少个字时才进行检测。 |
| delayTime | Integer | 否 | 1000 | 延时判定抢话情况,比如,设置为 1000,则表示同时一方开始说话 1000 毫秒后,再出现对话重叠才算作抢话,单位:毫秒 |
{
"interval":3000,
"threshold":4
}

8、角色判断(ROLE_CHECK)
该算子较为特殊,需要涉及到 check_range 的改动,详见完整的条件配置示例:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| target_role | String | 是 | 客户 | 指定目标句子的角色,可选值为:客服、客户。 |
{
"cid":"1",
"lambda":"1",
"check_range":{
"absolute":true, // 固定值
"alSentencesSatisfy":true, // 固定值
"range":{ // 指定要检测的句子位置,from 与 to 的值需要一致
"from":2,
"to":2
}
},
"operators":[
{
"oid":1,
"type":"ROLE_CHECK",
"param":{
"target_role":"客服"
}
}
]
}

9、非正常挂机(DURATION)
根据最后一句话的角色,以及最后一句话的结束时间到挂机的时间间隔来判断是否为非正常挂机,此时 check_range.range 中的 from 和 to 都需要指定为-1,来表示检测最后一句话,详见完整的条件配置示例:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| interval | Integer | 是 | 5000 | 表示最后一句话结束时间到挂机时间的时长(毫秒)。 |
| compareOperator | String | 否 | gt | 指定 interval 比较方式,gt:大于,lt:小于,默认为 gt。 |
| beginType | String | 是 | DIALOGUE | 固定传 DIALOGUE。 |
| target_role | String | 否 | 客户 | 指定最后一句话的角色,如果为空则代表任意角色。 |
{
"cid":"1",
"lambda":"1",
"check_range":{
"range":{
"from":-1, //固定为-1,表示检测最后一句话
"to":-1, //固定为-1,表示检测最后一句话
}
},
"operators":[
{
"oid":1,
"type":"DURATION",
"param":{
"interval":3000,
"beginType":"DIALOGUE",
"target_role":"客户"
}
}
]
}

10、录音时长检查(DURATION)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| interval | Integer | 是 | 5000 | 指定录音时长(毫秒)。 |
| compareOperator | String | 否 | gt | 指定 interval 比较方式,gt:大于,lt:小于,默认为 gt。 |
{
"interval":60000,
"compareOperator":"lt"
}

11、能量检测(ASR_EMOTION)
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| maxEmotionChangeValue | Integer | 否 | 3 | 能量值,取值范围:1-10。 |
| checkType | Integer | 否 | 3 | 检测方式,可选值:1(相邻句能量波动);2(最大能量跨度);3(能量范围检测),默认值:3。 |
| compareOperator | String | 否 | gt | 大于还是小于,可选值:gt(大于);lt(小于),默认值:gt。 |

12、通用检测模型(EMOTION_MODEL)
由系统内置的算法模型进行分析,目前可检测的类型有:辱骂检测模型、高危检测模型。
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| pvalues | List | 否 | ["ruma01"] | 检测的类型,可选值:ruma01(辱骂检测模型);goawei01(高危检测模型),默认值为["ruma01"] |

13、客户检测模型(CUSTOMER_CHECK_MODEL)
由系统内置的算法模型进行分析,目前可检测的类型有:扬言投诉客服、扬言找客服主管、质疑客服态度差、内部投诉检测、公共舆情检测。
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| pvalues | List | 否 | ["tousu01","zhaozhuguan01"] | 检测的类型,可选值:tousu01(扬言投诉客服);zhaozhuguan01(扬言找客服主管);zhiyitaidu01(质疑客服态度差);internal_complain01(内部投诉检测);public_opinion(公共舆情检测),默认值为["tousu01"] |

14、客服检测模型(ABUSE_MODEL)
由系统内置的算法模型进行分析,无需配置 param。
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| pvalues | List | 否 | ["jifeng01"] | 检测的类型,可选值:讥讽客户检测(jifeng01),默认值为["jifeng01"] |

二、规则的配置信息字段 RuleInfo 说明
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| rid | String | 是 | 1 | 规则的 ID,必须数字字符,此数字在规则上传后会被修改为系统自生成 ID。 |
| lambda | String | 是 | 一个条件:"",多个条件:a&&b&&c | 规则中条件的逻辑关系,由条件 ID(cid)与逻辑运算符(与、或、非)组成的表达式,示例值中的 a、b、c 均代表算条件 ID(cid)。 |
| business | List | 是 | 具体内容参见下方的规则所属业务字段 BusinessCategoryBasicInfo 描述 | 规则的适用业务,可在新建规则页面获取,详见下图。若该属性为空,则设置为默认的“所有业务”。 |
| type | Integer | 是 | 1 | 规则的类型,可在新建规则页面获取,详见下图。 |
| triggers | List | 是 | ["a","b","c"] | 规则中需要返回内容的条件 ID(cid)。设置规则 ID 的话,命中结果后将会返回规则所命中的具体内容。 |
| Name | String | 是 | "用户可能要投诉" | 规则名称。 |
| scoreSubId | Integer | 否 | 3678 | 规则绑定的评分项子项的 id,如绑定评分项,则必须传入 ruleScoreType。 |
| ruleScoreType | Integer | 否 | 3 | 该规则所绑定的评分项是否进行计分(1:不计分,3:计分)。 |
| level | Integer | 否 | 2 | 重要程度,用于在复核页面对规则根据重要程度进行分类展示。取值:0(重度违规);1(中度违规);2(轻度违规),默认值:2 |
| fullCycle | Integer | 否 | 1 | 设置规则的生效时间的类型,可选值:0(特定周期生效,特定的时间范围内生效),1(全周期生效,始终生效) |
| effectiveStartTime | Date | 否 | 2021-03-04 04:05:05 | 规则生效时间为特定周期生效时的生效开始时间。 |
| effectiveEndTime | Date | 否 | 2021-03-06 04:05:05 | 规则生效时间为特定周期生效时的生效结束时间。 |
规则所属业务字段 BusinessCategoryBasicInfo 描述:
| 属性 | 值类型 | 是否必选 | 示例值 | 描述 |
|---|---|---|---|---|
| bid | Integer | 是 | 267202890 | 适用业务 BID,必须数字字符。 |

检测范围 range 使用说明
检测范围是通过一个数字区间来筛选出当前条件生效的范围,具体说明如下:
一、无前置条件时

1.{"from":1,"to":3},代表所检测角色所说的前三句; 2.{"from":-1,"to":-3},代表所检测角色所说的最后三句话; 3.{"from":3,"to":-3},代表所检测角色所说的正数第三句到倒数第三句。
二、有前置条件时
存在前置条件时,系统会将所有句子,以前置条件命中句为分割点,切分为三个段落:前置条件命中句之前的所有句子、前置条件命中句之后的所有句子、前置条件命中句前后的部分句子,详见下图中所标示的三个段落。需要您先选择一个段落,然后再通过数字区间在该段落内来筛选具体的生效范围。

前置条件命中位置之前(anchor.location 的值为 BEFORE)

1.{"from":1,"to":3},代表所检测角色在当前段落内所说的前三句(紧邻前置条件命中句的句子的是第一句) 2.{"from":-1,"to":-3},代表所检测角色在当前段落内所说的最后三句(倒数第一句到倒数第三句)(距离前置条件命中句最远的是最后一句) 3.{"from":1,"to":-1},代表所检测角色在前置条件命中句之前的所有句子; 4.{"from":0,"to":2},代表前置条件命中句当句,到所检测角色所说的第二句之间的三句话(只有在当前条件与前置条件的适用角色一致时,才可以使用第 0 句来定位到前置条件命中句当句,若角色不同,则不允许使用) 5.以上仅为使用示例,并非只能使用以上四种情况,总体来说,正数代表当前段落正数第几句,负数代表当前段落倒数第几句。
前置条件命中位置前后(anchor.location 的值为 AROUND)
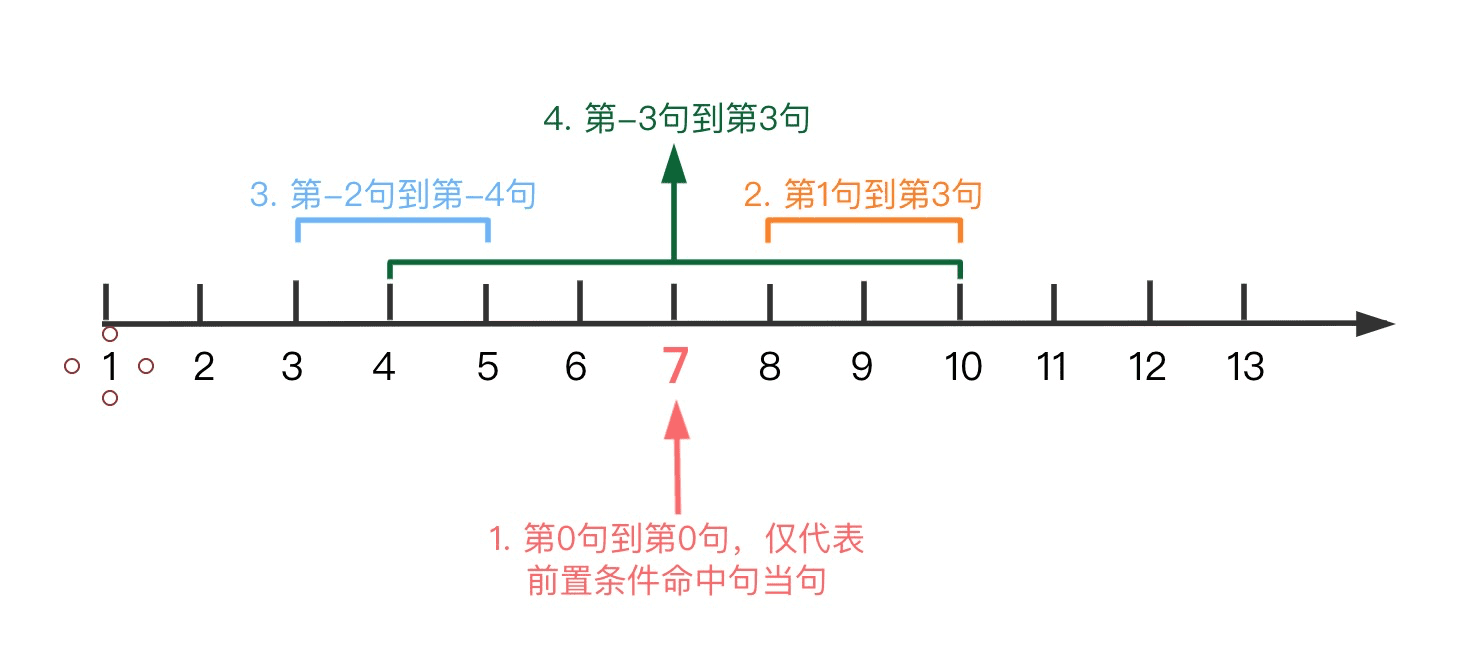
1.{"from":0,"to":0},仅代表前置条件命中句当句; 2.{"from":1,"to":3},代表当前置条件命中时,在前置条件命中句“之后”的所检测角色所说的第 1 句到第 3 句; 3.{"from":-2,"to":-4},代表当前置条件命中时,在前置条件命中句子“之前”的所检测角色所说话术的第 2 句到第 4 句; 4.{"from":-3,"to":3},代表当前置条件命中时,在前置条件命中句子“之前”的所检测角色所说的第 3 句到“之后”的第 3 句; 5.以上仅为使用示例,并非只能使用以上四种情况,总体来说,正数代表前置条件命中句之后的句子,负数代表前置条件命中句之前的句子。
前置条件命中位置之后(anchor.location 的值为 AFTER)

1.{"from":1,"to":3},代表所检测角色在当前段落内所说的前三句(紧邻前置条件命中句的句子的是第一句) 2.{"from":-1,"to":-3},代表所检测角色在当前段落内所说的最后三句(倒数第一句到倒数第三句)(距离前置条件命中句最远的是最后一句) 3.{"from":1,"to":-1},代表所检测角色在前置条件命中句之后的所有句子; 4.{"from":0,"to":2},代表前置条件命中句当句,到所检测角色所说的第二句之间的三句话(只有在当前条件与前置条件的适用角色一致时,才可以使用第 0 句来定位到前置条件命中句当句,若角色不同,则不允许使用); 5.以上仅为使用示例,并非只能使用以上四种情况,总体来说,正数代表当前段落正数第几句,负数代表当前段落倒数第几句。
返回参数
| 字段名称 | 字段详情 |
|---|---|
Codestring | 结果代码,200 表示成功,若为别的值则表示失败,调用方可根据此字段判断失败原因。 示例值:200 |
Messagestring | 出错时表示出错详情,成功时为 successful。 示例值:successful |
RequestIdstring | 请求 ID。 示例值:4987D326-83D9-4A42-B9A5-0B27F9B40539 |
Successboolean | 请求是否成功。调用方可根据此字段来判断请求是否成功:展开详情 示例值:true |
Dataobject |